This post title might look mightily like the post I made in January it is related, but we're going to discuss a different part of my Entity Component System and that is the containers backing my type registration and the actual values stored per component.
I've seen a few different entity component systems and I'll draw parallels with a few well known public domain ones.
The first is EnTT, it uses the same principles as my system which are sparse sets to store the metadata in regards the components per entity, my implementation also uses sparse sets however inspecting their code repository file names alone you can see maybe three container types a dense set, a dense map and a table.
I have known maps used to point to vectors of stored components such that the entity handle or id is the index into the components it contains, and then all the other vector entries are nulls (or otherwise empty).
And then in yet other systems I have seen a fixed number of components (64) possible being represented by binary flagging or bitsets to indicate the presence (or absence) of a component on an entity, then a linear storage of each component in a fixef size array. This was a curious implementation, relying on Frozen to give constexpr & consteval Ecs ability to a certain extent at compile time.
My implementation started with the need to map the types (just any type) and then to allow those types to assigned to the entities, very much the sparse set model of EnTT and its cousins out there.
Why not just use EnTT? Well, where's the fun and understanding built out of that?
So where did I begin? Well, I began by just using a std::map, std::unordered_map and std::vector and a piece of hashing code to convert the type to a compile time evaluated id code; so I can for any type get a 64bit number which is its unique (or nearly unique) hash. I am not using RTTI and infact compile with this disabled for speed.
With my types mapped and components going into the entities and being able to see which types were assigned to an entity (see January's post) I set about looking at more specialised containers; and finally we reach the meat of this post... Or should I say Paper?
As my self-review, redesign and frank improvements began by the careful selection of the AVL Tree as my container of choice, a self balacing binary search tree, often lumped in with Red-Black trees. I had spent a little time in 2019 invaluating a red-black tree implementation for work for an ex-explorer, and watched on as a collegue did the same evaluation for my current. I had not been best impressed with the lob-sided effects in the former, and the latter went with an off the shelf implementation from EASTL.

My reading began with a few white papers, a couple of older text books, the STL guide and finally a read through the second edition of Grokking Algorithms by Aditya Bhargava.
This final read cemented the AVL Tree as my target container, and I set about implementation from the books examples.
My first addition was to include a visualization pass outputting .DOT format diagrams for passing through GraphViz... And so it was the first output, inserting an "A" into a new tree appeared:

I find these tree diagrams most full-filling, and had to research the trick to lay the diagrams out as an actual tree like this, but soon I had test cases galore.

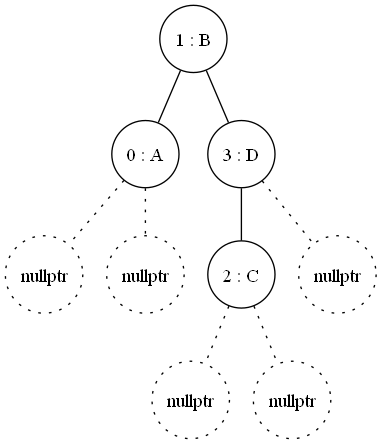
Inserting a second item and then a third, where we see the tree rebalance itself:

This rebalancing is the strength, I can take all the inserts of new types at the start up and then balance once; cost once, to get much faster look up than hashing every time and traversion a tree.
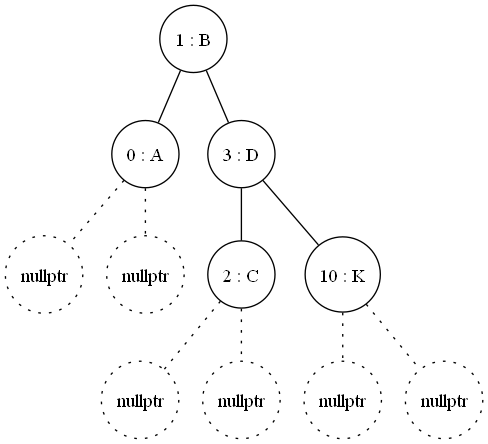

My code to flatten and allow this traveral is not very optimal, it can only really allow you to pre-allocate the correct number of keys to then follow. But again if the structure is not changing often (which is it now with type registrations) then it becomes the most optimal runtime solution I found.
Only the Frozen in compile time version, with its inherant more complex compile & lack of debuggabilty was faster. But then anything you can pre-compute is going to be faster.
I did however find an edge case, depending on the order of insertions, and hence when rebalacing happens, the same data can result in variants on the shape of the tree. Take the name of my wife and some of my pets....


I had to decide what constituted equality, this is where I resorted to a left-right linear traversal per node and this results in an equiality check; it's not quick, and not really intended for production code to use, it is simply part of my test suite.
This difference, or cardinality one might say, is a temporary effect on the data, and I wondered whether it would have a knock on effect for determinism in my code.
As you may guess, one tree in traversal (key) order and then reloading could dramatically change the order of the tree node relationships, as such I could not rely on the direct pointer (or dereference) to any node over another, no instead the key value was literally key.
I found this effect of saving and reloading to "rebalance" the tree had the benefit when documenting my registered entity types that having gone through this save & load the graphs output where the same, I termed this a sanitzation pass on some of my data and I'm sure I'll return to it.
The last feature I added to the AVL tree implementation was the removal of nodes, this may sound trivial, and to an extent it is.
However, I had programmed the use of my AVL Tree with "forward intent" this is a rather short sighted way of working that you produce code only to do the exact features you need, you either ignore, or ticket and backlog the "nice to haves".
So it was after a fortnight of working on the Containers, the speed, the hashing within my engine, not to mention the test suite & graph viz pass I had dozens of types registrations, thousands (probably hundreds of thousands of each entity type being created)... And then I needed to destroy an entity.

Quite simply it never came up, I'd forgotten it as a feature and test case, because sometimes when you're working at near midnight tinkering with tech, you do forget things.
So there you go, my little sojourn into AVL Trees for my home engine Ecs implementation, and I learned a lot along the way in just this one little case of my own making.
Anyone out there looking to take up programming, do it, just start simple and move up along the way. I'd say start simple, with a language which can just run on any box, without too much hassle, just a text editor and a language to use; like python. Progress in small steps.

