A blog about my rantings, including Games, Game Development, Gaming, Consoles, PC Gaming, Role Playing Games, People, Gaming tips & cheats, Game Programming and a plethora of other stuff.
Viewers of my YouTube channel will know I have horses, we lunge, ride, trap & carriage drive and generally really enjoy them, keeping them and ourselves entertained. They are pets and massive parts of our lives.
The eagle eyed of those viewers will have noticed over the last two years we have been training our Cleveland bay, he arrived from the breeders Mr & Mrs Orange at Kenley Cleveland Stud. His name is Nova.... Or Kenley Supernova, and we had to join the Cleveland Bay Horse Society to own him.
He is that rich bay colour with the striking black socks on each leg and a strong black main and tail, the absolute standard for the Cleveland Bay Breed; accept no less! He arrived with some of the biscuit fringe colours of a foul and he has been slightly behind on his teeth changing from baby to adult, but otherwise he is a big boy, today measuring at least 16hh3 (hh = hands).
Nova's character is a quirkly one, for the most part he is all over humans, he investigates you and things around him... Being very interested and unlike many horses he is mindful, he doesn't just blindly panic but instead thinks about the challenges he encounters.
Again this is a trait of his breed, to be mindful, steady temptered and is one of the reasons they are so popular in the driving role today; notably for the Royal Family, if you see a bay coloured hosed with the black mane, tail & socks, pulling a carriage for the King, well it'll likely be a Cleveland Bay.
When we started training Nova it was literal baby steps, head collar training, leading him around the field, past various bric-a-brac:
Since that video was taken I have lost a bunch of weight.... Nova has not, he's grown and grown, his shoulders coming out and strengthening right now in October 2025. You can see here is withers are just around my shoulder height, today they're up around my ear and he is just such a much bigger animal.
Once the head collar training was done we moved onto a bridle, at first with a plastic bit, but quickly he had an upgrade to steel, with a soft articulation in the middle:
All of this training was done in house by ourselves, we'd done much of this before with Gerty, but never with such a young horse, still growing, so it has been fascinating to see his mind growing with his skills and size.
The next step was to decide how to best approach him into driving.... And long reigns were the best way to move forward, with the help of a local trainer we began introducing him to new equipment:
Two sessions later and it was my turn to keep this practice up.... As you can see by the state of the grass this was in the burning hot summer of 2025.
So it was I found myself behind him rather than leading him...
Which is a very alien thing for a horse to experience commands from literally out of sight as you walk in their rear blind spot, however, the Cleveland Bat genes run strong in him and he was extremely comfortable with this extremely quickly as his quality shone.
Graduating to road practive soon after, and I took him out without our trainer just this very morning...
All of this is not just about owning a horse, nor just owning a Cleveland Bay, so many people claim their horse is a CB it's hard sometimes to bite ones tongue as a true CB is a very special animal, and you have to have the rare breeds passport, Cleveland Bay Horse Society member ship and all the bloodlines clearly defined to state your horse is a CB.
And the bloodlines are very important, Mr & Mrs Orange who bred Nova are massive figures in the breeding programmes, advocates for the breed and the CBHS. Nova was gelded without saving any semen from him, sometimes I am sad about that, but we could simply not have had a stallion at our yard.
So instead of spreading his genes I write this post to spread the true word about the Cleveland Bay, our experience with Nova has been so rich and rewarding and we have decades to come with him.
He will drive out pulling a carriage and we hope to ride him too, weight loss programmes and will power willing!
He has been an absolute powerhouse of mental development, horse wise he is very clever.
And so I bring my post to a close with this post from Mrs Orange:
This is a topic I have visited a few times over the years:
2016, 2016 on SDL2, 2019, 2023 on control block, and I visited it professionally on the now cancelled AAA MMO Game Engine with Zenimax Online; the specific pattern within which came from my original 2016 post, just with a few tweaks and expansions over the years.
Its just one of those things which comes up time and again in the C++ space, much like my crusade against return early in performance code... cough.
And it came up again just this week, where given a coding test I immediately did not like seeing raw pointers being used, so quickly refactored it to use a factory create pattern, except I was in a rush and didn't have the luxury of a whole game engine backing me up.
So denuded of even my own post I quickly used a different approach, so use a hidden (private) member struct in the constructor. The constructor remains public so std::make_shared or std::make_unique can access them without hinderance from the static create factory member function, but that a regular user can not use a flat "operator new" as they can not access the private struct.... Sounds complex, but it's really not, and you will even find this exact pattern on CPP Reference sites across the web, let us quickly output an example (and I'll assume you've taken a look at my prior post from 2016 above for the actual "shared pointer friendship" I would prefer).
And so with this code we can only get a Ptr instance here from the static Create call.
Now I've set the scene, what am I asking myself? I'm asking what is the compile time and what is the runtime effect of these two patterns?
Compiletime my suspicions are that the shared_pointer friendship stuff in my original post is more weight to carry, there's a macro in my more complex implementations, so that's pre-processor overhead, there's expansion of the code at compile time.
But there's also this HiddenInternal in this new, simpler, implementation based solve; I believe there will even be compiler ellision of the HiddenInternal as its empty and does nothing; I just need to observe and understand this topic better.
Lets start with Compiler Explorer and my first confirmative discovery, just as I suspected, the compiler is very smart smart and it will easily see a trivial class such as mine above, or one with a single member, and fold it away to nothing in compiler ellision.
And this is a great thing! It proves at zero runtime overhead whilst we have code fully communicative of the intent, self documenting code is a wonderful thing, and this is an interesting and eye catching pattern in the code.... Such that I believe even a new set of eyes meeting it would appreciate there is something special intended and they would take care to use the class properly, avoiding memory leaks for us along the way.
Good code health is as important as the final result, I especially take pride in code which can run a long duration. I've always worked on long lived project timelines.
So HiddenInternal can result in no overhead when the class is trivial, what about when the class is complex?
The first thing I notice is that the factory creation function itself generates no code, yet we benefit from its intent at compile time and in the usage. There is of course the control block creation for the shared pointer in this instance and I hold that in my mind, but the cost to pay back in intent of the code far outweighs the control block.
The constructor itself is interesting....
Removing the HiddenInternal gives no difference, so the compile has still removed the empty class, but enforces it's use in the code... This is a total win-win... The cost at compile time, one compile time ellision in one translation unit which is neglegable.
The runtime overhead zero.
What about the preprocessor and friendship.... The friend keyword itself is zero cost, the wrapping of it in a macro is therefore arguably a different conversation to have. Resolving a friendship however is not so cost effective, the friend keyword adds a symbol, typically with a cost of O(1).
The look up from any other resolve is therefore either going to be O(1) or O(log N) where N is the number of other appearances of the name, this look up is going to be the compile time cost. In practical terms this is going to be a very small duration, perhaps even below measurable in the pantheon that is a build across multiple cores.
A friendship link itself however costs nothing in code generation time, so we do not hold up the compile per se, we do however add a cost in the symbol table build.
Once something is in the symbol table it will result in complexity when refactoring code, potentially more rebuilds if the friendships, or classes within change.
In conclusion, if I have the option to set up a friendship to the underlying control block (see 2016) I would, but equally to keep the local complexity low I would also consider the Hidden private member class as a "trick".
I'm back on my home game engine and I need an area damage effect, which can apply to all the members of a team/party.... The trouble? How to synchronize this over a network connection.
First of all, I know for certain that the server running my game world knows the center of the effect, and it knows the radius of the effect. And it does tick the effect application against each player whether their client can visually see the effect - it appears in their combat log text immediately.
So the mechanics are there, the clients however, all run at different rates, they're in different locations world wide, with different latencies to the servers source of truth.... And so I need to now think about how I am going to tackle the issue of each player seeing an effect.
Simplicity first, the effect is just going to be represented by a wireframe sphereoid, it'll be a smooth shaded sparkles dripping effect later.
This quiets my engine engineer smooth brain some what and I now just need to synchronize the expansion from the center to the maximal radius of the effect, this will turn up at the clients from the server at any time after the effect is registered as affecting the players on the server... This maybe unfair, however, there is reason behind this in the design - the player will know the effect is going to be cast as there is pre-warning from the caster... They need to learn that and move before they see the effect basically.... That is, they need to be smart.... I know I know this is a cheap answer, but I am all about cheap answers to problems today - and in my gameplay loop, seeing the caster "spit" this effect and moving before it expands into a cloud of hell... is pretty rewarding.
So I have a time point, on all clients they know when the effect begins, they know the maximal extent and they know the center of it....
What I am thinking about now is the client side only, so without any network traffic, an entity definition for the effect which the client has pre-loaded into some dictionary of effects to execute, and this contains a rate per millisecond from the start time and the effect system has to linear interpret along the line.
I am thinking about designing some form of easing curve authoring for the client effect system - and I'll likely reuse this in the animation system - whereby I can try different easing curves.
The system interpreting along the line could be more than a lerp too, again that'll be down the line.
Replaying, reversing or otherwise on such a defined effect is going to be quite interesting as reversing the delta will allow me to contract it again.... Though time-line ordering is to be forwards chronologically only for my game play, that maybe a feature I want to play with in future.
What's the problem then? Yeah, it sounds like I have a handle on what I want, except.... I've assumed all the way through my thinking that the effect is fixed, known and defined up front.... The problem?
I want to scale the effect with the power of the caster, and this is not known up front, sure I can just add a float and multiply by 0.5 for half power or anywhere along that scope, heck I could even scaled the enemies power by some easing function as well and combing the power function along that line with the rate of the effect.... So there are answers to be had.
My problem is randomness, when it's random, things look wrong, they don't feel right when playing them and the rewarding feeling I had from the fixed function gameplay doesn't turn up... It's in some fort of metaphysical uncanny valley which I can't quite explain doesn't feel right.
I was intrigued recently by a video from LindyBeige about Roman War Waggons, during which he brought up that some folks argue about how a horse might have been tacked to a wagon in that era.
Where by some etchings show only a single "pole" attaching a wagon to oxen or horses.
I looked at the image and wondered perhaps if it was a full length trace, which would be on the wagon frame, but he was totally right about the perspective and the image clearly being fanciful.
I today therefore was having a think about whether swingletrees would have been in use, they certainly are in ploughs and oxen drawn materials from the medieval period; I've read and seen etchings which come from contemporary sources.
My driving position has a single articulated pole, but this is not for the driving power, that is just for direction; and the swingletrees, to the horse traces, they are the power.... so there's a very intricate interplay between all of them to keep things in balance....
And to be honest.... I reckon in some form, this would have existed just a few years after starting to use horses, let alone a few dozen millennia as the turn to the common era would have been (year 0 by the Gregorian Calendar).
No, I'm not talking about horses this time.... Lets talk engineering, what is a fence? A memory fence or barrier is used to order reads and writes around certain operations called Atomics.
This ordering ensures that both communication of the value from the register in the processor is correct between all the cores/threads running and the cache within the chip as a minimum, and may even leave to a full flush to the main memory (though that is far longer in cycle).
These can take tens to hundreds of cycles to leap the value over the barrier.
In C++ the most common two, or certainly which I encounter most often, are fetch_add and fetch_sub, using them to control everything from the shared count on a resource to the control gating on fixed sized "high performance" containers.
And there in lies the rub, these operations cost a lot of cycles just to increment or decrement a counter in many of my use cases, so why use them?
Well, that barrier within the chip, between the memory is very expensive if we compare it simply with the very cheap increment or decrement of a register itself, just the value in the register on the chip can change in a single operation instruction; sure it took others to load the register and it'll take yet more to store the result off, just as it would with the atomic; but on top of that you have no overhead in comparison with the atomic....
Until... Until you try to synchronize that flat increment or decrment, sure then that code is going to be far faster, however, it's not thread safe, not at all, the atomic already is (when ordered correctly)...
In order to protect a flat operation one therefore has to wrap a separate lock, or mutex, around it which is far far more costly than the atomic operation. This difference is called the "contention cost", the contention cost of an atomic is simply in the number of steps, lets look at code:
The atomic addition, the CPU itself will execute
lock xadd [or similar]
This itself is a single instruction, it may result in multiple cycles of the CPU to complete, but it is a single instruction. It ensures unique ownership of the cache line (usually 64kb) within which this variable resides, and means if you perform an operation anywhere in that cache line you will be making optimal operations. As the CPU can perform all the atomic updates in that 64kb block without having to fetch another, this is really useful when there are a few cores (2-8 on average) accessing an area of memory and event holds up when scaling out to more cores.
A mutex however, has to be controlled wholly separately from the increment, so we may end up with C++ such as this:
std::mutex lock;
uint64_t count { 0 };
{
std::lock_guard<std::mutex> lockGuard { lock };
++count;
}
The execution here will have to acquire the mutex in a harsh manner, internally this is an atomic; if the pathway here is lock-free, then the atomic operation underlying the mutex is the only added cost. However, and this is a HUGE however, if there is contention, someone else already has the lock then this lock-guard has to spin wait... And it's the contention, the other thing having the mutex locked, which adds the cost.
So you're essentially gambling on whether you have a value not contested before the lock or not, and in both cases you take on the cost of an atomic operation; so for my codebase and it's uses across sub 32 core machines means that an atomic is much more efficient in most all my use cases.
A mutex however is far more useful when protecting more than a single register, when protecting a whole block of memory, a shared physical resource (like a disk) or just a complex structure you can only use a mutex around it.
All this sort of eluded me earlier this evening, I was in the middle of a technical conversation and I bought up the atomics backing a shared_pointer in C++ and immediately just sort of lost it, my memory drifted far far away and I have to admit to waffling some.
I even forgot about weak_ptr deriving from a shared_ptr and it's uses to "lock" a new copy of the shared_ptr and so passing ownership by weak pointers.
But it came from a very specific conversation about Unreal engine, about TSharedPtr... Not a structure I myself have used, and for the life of me I could not think why not, I just knew not to having been told...
And of course here I sit a few hours later and I know why, it's not thread safe... TSharedPtr in Unreal is not threadsafe, and why is it not? Well because it does not protect its internal reference count with an atomic, no it's just a flat inc and dec of a count integer register "for performance purposes".
So sure if you're inside one Unreal system, on one thread, then yeah you can use the TSharedPtr, but it's utility is much reduced to my eye, and you would want to perhaps look at other ways to hold your resources in that thread, even in thread local storage rather than in the engine heap.
The moment that TSharePtr crosses a barrier, then you're far far away from thread safe.
So what do you use a TSharedPtr for? The documentation says "To avoid heap allocation for a control block where possible"... Yet it contains an explicit reference count, which is in a control block, and underlying it is a flat "operator new" and it uses only default deletion via the flat operator delete.... So my non-Unreal expert brain says "Why use it at all".
Hence when asked earlier today my memory was over the fence and far far away.... Of course now, it's all returned and... yeah I just sat through two hours of TV mulling this over.... and had to come write something down before I went a little bit odder than usual.
Tomorrow let me regale you with my story about forgetting how to load a crash dump and the symbols files and explain myself properly, despite doing that particular duty about a hundred thousand times in my life. Hey ho, a technical conversation in which I fouled up, one is only human.
I've had one of those moments where I have posted and just feel the need to elaborate on the topic, I enjoy that feeling, so here goes.
I posted about prototyping and that is such a very loaded word and indeed quite a broad subject, I'm not delving into anything specific in that field; however I am going to talk about my intent in why I enjoy revisiting, refactoring and the benefits I have found with those efforts.
First, refactoring, itself a simply enough principle, you can both simplify something and make it more readable, more maintainable, you can also refactor to take advantage of new advances from other technologies; perhaps a new library, or new framework, which achieves the same effect as your code written by your (perhaps) smaller team; and in my opinion going with a library written and peer-reviewed in use with hundreds, thousands or even millions of other users is really a boon to your assurance of its use over your own individual effort.
[Yes, writing your own can also be good].
Second, revisiting, this is really the meat of the prior post; going back to your own code, or code in another part of a large system, write it your way, update the coding standard, conform to emerging or simply new best practices. Doing this is really quite interesting, and you can through the magic of software do it side-by-side.
You can refactor the function "foo" with your own "bar" then simply swap the two function names and voila the original system process flow now uses your new code, and you can test it, try it and crucially roll back if you need to.
This is a great tool and the real reason I wanted to highlight the practice.
It isn't just limited to individual benefits, it can benefit team members around you, to both have the practice demonstrated to them and used as a catalyst to encourage them to engage with the code more widely; too often I see engineers rabbit hole into a single field, or become the defacto owners of only one vertical slice of a code base.
Such occurrences can lead to friction, what happens if they are absent through say illness or holiday, a problem occurring in their field becomes very important, the pressure ramps up on them, on the team and ultimately the project. And there's no pressure value to relieve this, you rely solely, heavily, on that one person. What happens if they do not like this work environment? You are unable to support them! They feel they are trapped! There are so many negative effects from the sole-engineer/owner model that again I am beginning to touch on a whole other field of the software engineering puzzle.
So refactoring efforts to me become a way to familiarize multiple engineers into the general planform of a project, large or small, it helps each engineer support every peer in the group; they find common things to discuss, or collaborate on.
To me, working through a codebase, as a group, in cooperation is really important.
And it starts with one person in front of one screen tinkering and discovering.
In software engineering I am one of those people who like to embrace change, I will in my own projects and even in professional situations (time permitting) stand up a new version of existing functionality in a side-by-side manner to try out new things, seek better solutions or performance or simply to understand how someone else's solution solved for the problem at hand.
This mentality broadly sits under the "Prototyping" method of software engineering, however, prototyping itself often says you should create a prototype in a wholly other language or platform than your target; a little like when planning to make a game in a brand new custom game engine you might want to prototype in an existing one, so benefit from both your own engineering expanding your eventual product, but building confidence and a marker post for performance & the content to which you can work.
The same is then true when I just want to elaborate on a single target piece of code and rework it.
I say all this because I like change.
What I can not abide however is change simply for changes sake, changes or reengineering something for no purpose.
The biggest villian in this space for me, sadly, has to be Microsoft with the Windows Operating system.
The only reason I even still run windows is to test games I'm working on (not even to run those games in most cases).
And today they've drawn my ire by reengineering, for no purpose to me, nor benefit to any user the Lock Screen.
You could just Windows Key and L your way to exiting to lunch or to go away securely from your desk, it's a natural reaction for me to lock the screen, even when I'm working at home! So ubiquitous was I taught about security, through hard learned lessons and practical jokes.
So it irks me massively to return to my machine just now, find it has installed an update and now when locked I come to wake the machine it sits.... and sits... and does nothing... and nothing happens.... and you wait....
To the point I believed the machine was locked up or crashed.
When really it's opening four widgets on the lock screen.... Four..... Inane news articles which do not interest me, junk adverts and even the weather app I must have uninstalled three times on this machine, yet it returns constantly.
The delay? Yeah, it was off loading whatever framework it needed to show these embedded widgets.... Some Javascript framework taking a gig of ram no doubt, which has taken the lock screen of instant, consistent and functional usage to a dismal mess I am going to have to disable for my own sanity.
Microsoft, just NO, stop doing this.
Why the widgets? And then you remove them, after trying to figure out what's wrong and even with the value set to "NO" do not show me these widgets it still adds another app to the list of things it can show, it's so insidious; not to mention slow. And when you finally do disable these needless widgets?..... Oh it's still massively slow and doesn't work as it did before.
Yeah you sould press any key and wake the locked screen to give you a log-in prompt... now only escape seems to give me a log in screen.... I have no idea why that change was done, I presume whomever was tasked with this change just likes or was themselves used to using the escape key; but it's the many tiny little changes the gas lighting of "this used to work <that> way" only to find it changed - without any visual reconfiguration it just now works differently - it all just beggars belief.
I've had a little bit of a roller coaster few weeks, I would recommend anyone feeling life taking them and rushing them to try and find a minute for yourself, take a breath and slowly exhale.
When I started working as a programmer, my days began with a ritual that felt entirely normal at the time: over an hour of inbound commuting into the city, and then another long outbound journey home. Time, energy, money — all drained in the process. It was the cost of doing business, or so I thought.
Then the pandemic hit, and everything changed. Practically overnight, that daily routine vanished. The entire company transitioned to remote work in just a few days. Luckily, we had already laid some of the groundwork — tools, systems, and workflows that supported remote access. All we had to do was scale up.
And it worked. Customers experienced very little disruption, and internally, we barely missed a beat.
Now, years later, we’re still working remotely. And — here’s the thing — it still works.
Not just for the company, but for me. Personally. Deeply. In ways I didn’t expect.
More Time, More Focus, Less Waste
The first and most obvious benefit? I got my time back. No more two-hour round trips, no more standing on packed trains or sitting in traffic. That reclaimed time went straight back into my life — and into my work.
I’m more productive now. I’m more focused. I’m in control of my time, my energy, my attention. Sure, life shows up — a doorbell, a neighbour, or an unexpected distraction — but the tradeoff is still massively in my favour. I’ve spent time building out a dedicated workspace at home, optimized for deep concentration and comfort. It’s not a makeshift setup at the kitchen table. It’s mine, and it’s built for what I do.
With that setup, and without the daily grind of commuting, I find I spend more time at my desk, more time on task, and the quality of that time is better. It's not just about more hours; it's about more effective hours. My brain arrives to work fresh instead of depleted.
The Return-to-Office Push: A Puzzle
Despite all of this, there’s a message echoing out there in the corporate world: return to the office. The tone ranges from gentle encouragement to stern mandates. But I keep asking myself — why?
Why bring people back into expensive office buildings? Why shoulder the cost of maintaining spaces built for humans — with their endless needs for coffee, heating, lighting, safety drills, and ergonomic chairs — when the alternative is already working?
If a company needs physical infrastructure, great. Build a tech hub. Keep your servers somewhere secure, your dev environments humming. Machines don’t need water coolers or office parties. But humans — we’ve figured out how to work remotely, and for many of us, it’s been a genuine upgrade.
The Uncomfortable Truths?
Maybe not everyone shares this experience. Maybe not every job translates well to remote work. Maybe some people don’t have a dedicated space at home, or they’re working at the kitchen counter while the family or flatmates buzz around. Maybe their productivity really has dropped.
And maybe, just maybe, some of the voices calling us back to the office are those for whom remote work didn’t feel good — or didn’t look productive from their side of the camera. Managers who are used to seeing bums on seats might feel unease when they can’t “see” work happening.
I get it. It’s hard to manage outcomes instead of hours. It’s hard to trust that people are working when you can’t walk by their desk. But is that really a reason to ignore all the gains?
What Does the Data Say?
I’d love to dive into studies on this — real data about productivity in remote vs. office environments. But I want more than just headline numbers. I want to know:
What kind of work were people doing?
Did they have a dedicated workspace at home?
Were they experienced at remote work, or thrust into it overnight?
Because I believe my personal productivity boost comes not just from being home, but from investing in a space that lets me focus, and in habits that support remote productivity. Without that, maybe the experience would be different.
It’s Not One-Size-Fits-All
This isn’t a blanket statement that everyone should work remotely, or that every company should shut its offices. But it is a reminder that — for many of us — the shift to remote wasn’t a compromise. It was an evolution.
We cut out inefficiencies, reduced stress, and created more sustainable workdays. And that’s not nothing.
So, when I hear the call to return to the office, I pause. Not out of resistance, but out of honest curiosity: What are we returning for? Is it about culture? Control? Collaboration?
Because if it’s about productivity — well, for some of us, remote work already won that argument.
My Conclusion
Remote work isn’t perfect. But it’s real, and it’s working. At least for me — and I suspect for many others too.
Maybe it’s time to stop viewing remote work as a temporary measure or a compromise, and start treating it as what it has proven to be: a legitimate, powerful, and in many cases superior way to work.
Let’s be thoughtful. Let’s look at the data. Let’s listen to the wide variety of experiences out there.
But let’s not forget: commuting two hours a day wasn’t normal. It was just what we got used to.
Modular Ship Building system.... Yeah, so I've played about with compute shaders and high res oceans for, well for too long, I do want my game to have a low-poly feel so I've returned to focus in that direction.
Today beginning my modular ship building system, I can build a ship to place into the play space out of discrete pieces. Since I'm using an Entity Component System this is trivial, I just create the "ship" as a series of child entities of the one ship and each has a different model offset to just place the renderable where I want them.... Yes yes, lots of words, just go with me here.
I started with building out a Hull Model, then a bow and finally a stern, and set up a function to build a ship with a number of segments of hull capped with ... yes the bow and stern:
The result was extremely visually underwhelming:
However, it proves out four key piece of technology, first is my transform hierarchy code is working as expected the parent entity here positions all the sub-renderables.
The next is the entity creation utilities are working, with the components tagging bow and stern orienting the entity along the X axis as "Forwards".
Right in the middle is my new Obj loader and the vertex colour attributes; I've moved away from using a Texture map to look up the colour of a face, say from a texture like this:
I've moved to vertex colours, but may return to UV's and faces, we'll see when I reenable global lighting.
And the final piece of tech is my revamped ImGui display of all the entities in the scene; I'm looking at implementing a gimbal control for moving entities about more easily within a scene. This leads to the next piece of tech I am going to look at which is a scene editor, I need more play space defined, so land masses, buildings, objective markers, a compass display and of course to be able to control these new ships.... Watch this space.
This is a very hard post for me to write, not only am I personally and quite emotionally involved, but I am also still under a strict NDA and as such I can only point you to search the internet for many of the other leaks on the topic.
But finally I can perhaps explain why the number of blog posts I have been making has dried up; I often said it was because I was busy.
On January 2nd 2019 I walked into my first day of development on Project Blackbird as part of the core engine tech team with my employer The Multiplayer Group and as a founding member of the project with Zenimax Online.
The project as it stood the day it was cancelled was, is, stunning to look at. Alex Tardiff lead the standing up of a brand new renderer from the ground up, a brand new engine was also stood up along side this and the two interoperated superbly.
Early in the development we did a lot of research, selecting technology, containers and performance considerations; we stood up a project with a handful of people and scaled it sucessfully to hundreds. Standing up a new engine, a new renderer and the complete tooling stack for it is no mean feat. Think an almost skunkworks kind of deal, with just a dozen members standing up something like Unreal 4; then scaling it out to something which in my opinion visually looked better than Unreal 5, with all the tooling, all the content creation to roll out experience after experience coming together nicely... Within just over six and a half years!
The experience of playing was incredible, the mechanics in the game unique, the world in which the player experienced the game mezmerising.
The team was amazing, sure we had ups and downs, but we were one under the Blackbird banner and until 4:03pm Wednesday 2nd July 2025 we believed there would be a cornerstone gameplay experience delivered on PC, XBox and Playstation 5.... Alas, no more.
As you may understand I am extremely upset by these events, finding constant moments of almost grief, automated message reminders still appearing from headless accounts, sprint goals all planned out but no actions to make, I am bereft of purpose, I am emotional, I was a BLACKBIRD.
This post title might look mightily like the post I made in January it is related, but we're going to discuss a different part of my Entity Component System and that is the containers backing my type registration and the actual values stored per component.
I've seen a few different entity component systems and I'll draw parallels with a few well known public domain ones.
The first is EnTT, it uses the same principles as my system which are sparse sets to store the metadata in regards the components per entity, my implementation also uses sparse sets however inspecting their code repository file names alone you can see maybe three container types a dense set, a dense map and a table.
I have known maps used to point to vectors of stored components such that the entity handle or id is the index into the components it contains, and then all the other vector entries are nulls (or otherwise empty).
And then in yet other systems I have seen a fixed number of components (64) possible being represented by binary flagging or bitsets to indicate the presence (or absence) of a component on an entity, then a linear storage of each component in a fixef size array. This was a curious implementation, relying on Frozen to give constexpr & consteval Ecs ability to a certain extent at compile time.
My implementation started with the need to map the types (just any type) and then to allow those types to assigned to the entities, very much the sparse set model of EnTT and its cousins out there.
Why not just use EnTT? Well, where's the fun and understanding built out of that?
So where did I begin? Well, I began by just using a std::map, std::unordered_map and std::vector and a piece of hashing code to convert the type to a compile time evaluated id code; so I can for any type get a 64bit number which is its unique (or nearly unique) hash. I am not using RTTI and infact compile with this disabled for speed.
With my types mapped and components going into the entities and being able to see which types were assigned to an entity (see January's post) I set about looking at more specialised containers; and finally we reach the meat of this post... Or should I say Paper?
As my self-review, redesign and frank improvements began by the careful selection of the AVL Tree as my container of choice, a self balacing binary search tree, often lumped in with Red-Black trees. I had spent a little time in 2019 invaluating a red-black tree implementation for work for an ex-explorer, and watched on as a collegue did the same evaluation for my current. I had not been best impressed with the lob-sided effects in the former, and the latter went with an off the shelf implementation from EASTL.
My reading began with a few white papers, a couple of older text books, the STL guide and finally a read through the second edition of Grokking Algorithms by Aditya Bhargava.
This final read cemented the AVL Tree as my target container, and I set about implementation from the books examples.
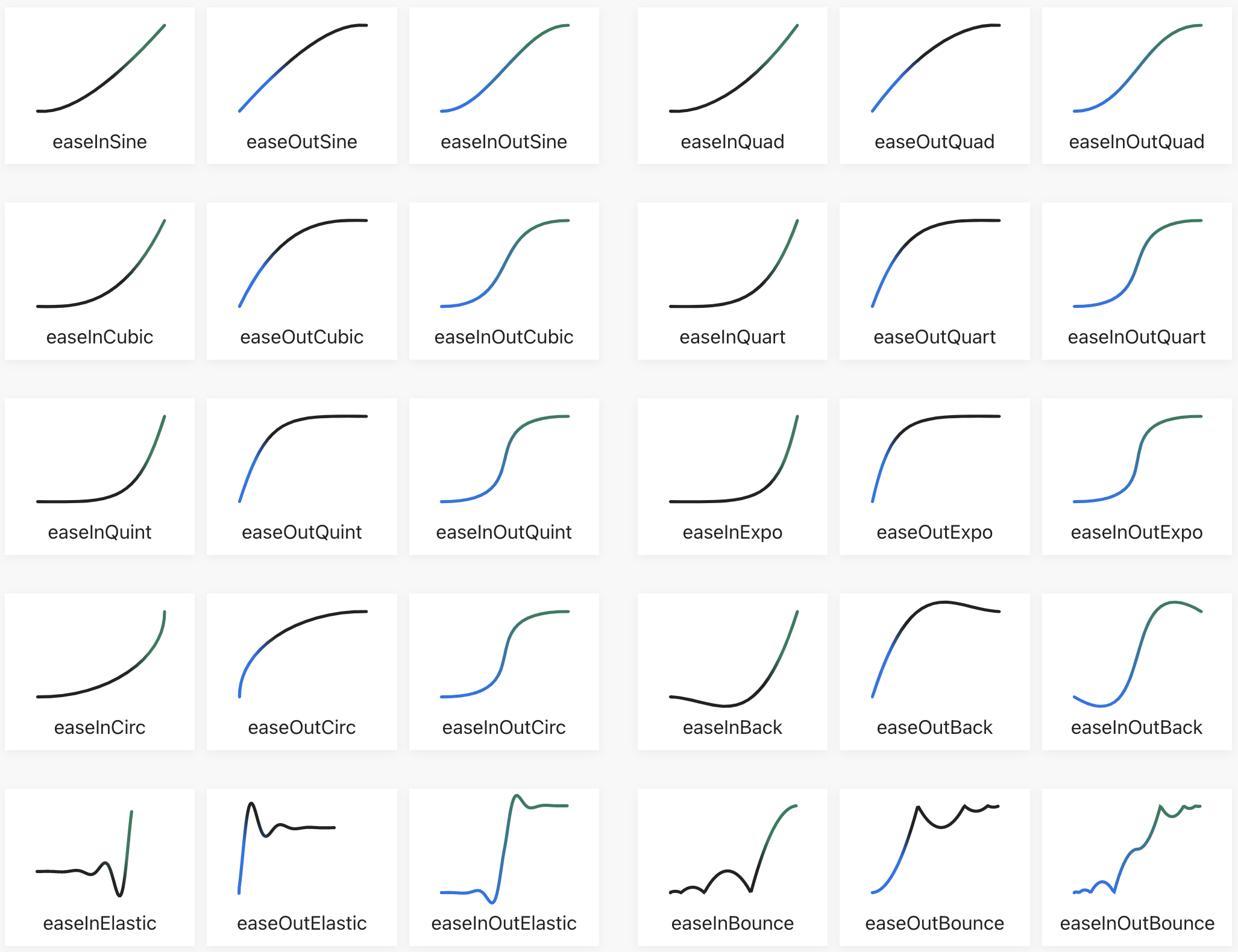
My first addition was to include a visualization pass outputting .DOT format diagrams for passing through GraphViz... And so it was the first output, inserting an "A" into a new tree appeared:
I find
these tree diagrams most full-filling, and had to research the trick to
lay the diagrams out as an actual tree like this, but soon I had test
cases galore.
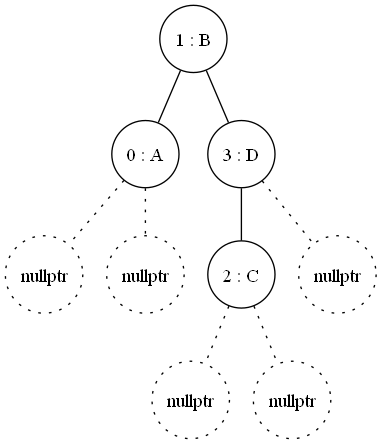
Inserting a second item and then a third, where we see the tree rebalance itself:
This rebalancing is the strength, I can take all the inserts of new types at the start up and then balance once; cost once, to get much faster look up than hashing every time and traversion a tree.
If you can't spot the re-balancing in the leaves, just watch for the root changing, once it does take all the left arms to find the lowest level index (zero) containing 'A' and then march parent, right, common parent and so on and so forth.
My code to flatten and allow this traveral is not very optimal, it can only really allow you to pre-allocate the correct number of keys to then follow. But again if the structure is not changing often (which is it now with type registrations) then it becomes the most optimal runtime solution I found.
Only the Frozen in compile time version, with its inherant more complex compile & lack of debuggabilty was faster. But then anything you can pre-compute is going to be faster.
I did however find an edge case, depending on the order of insertions, and hence when rebalacing happens, the same data can result in variants on the shape of the tree. Take the name of my wife and some of my pets....
Compare this with the same data inserted in a different order:
These two trees contain the exact same data and same key set; but they are different in form.
I had to decide what constituted equality, this is where I resorted to a left-right linear traversal per node and this results in an equiality check; it's not quick, and not really intended for production code to use, it is simply part of my test suite.
This difference, or cardinality one might say, is a temporary effect on the data, and I wondered whether it would have a knock on effect for determinism in my code.
As you may guess, one tree in traversal (key) order and then reloading could dramatically change the order of the tree node relationships, as such I could not rely on the direct pointer (or dereference) to any node over another, no instead the key value was literally key.
I found this effect of saving and reloading to "rebalance" the tree had the benefit when documenting my registered entity types that having gone through this save & load the graphs output where the same, I termed this a sanitzation pass on some of my data and I'm sure I'll return to it.
The last feature I added to the AVL tree implementation was the removal of nodes, this may sound trivial, and to an extent it is.
However, I had programmed the use of my AVL Tree with "forward intent" this is a rather short sighted way of working that you produce code only to do the exact features you need, you either ignore, or ticket and backlog the "nice to haves".
So it was after a fortnight of working on the Containers, the speed, the hashing within my engine, not to mention the test suite & graph viz pass I had dozens of types registrations, thousands (probably hundreds of thousands of each entity type being created)... And then I needed to destroy an entity.
Quite simply it never came up, I'd forgotten it as a feature and test case, because sometimes when you're working at near midnight tinkering with tech, you do forget things.
So there you go, my little sojourn into AVL Trees for my home engine Ecs implementation, and I learned a lot along the way in just this one little case of my own making.
Anyone out there looking to take up programming, do it, just start simple and move up along the way. I'd say start simple, with a language which can just run on any box, without too much hassle, just a text editor and a language to use; like python. Progress in small steps.
Today Microsoft Outlook is back at it's old habits of being utterly dreadful.
So I need to put "29th" with the the in superset, it used to do this itself, but not any more.... now you get "2 h" in normal and "9t" in superset... Dreadful!
I've literally been inundated by a message about my XVE project, specifically calling out why I have the temerity to describe it as an "Engine when it looks do basic?"
My over simplification in reply being that an engine can be anything you please, the engine is simply the framework within which the content can execute.
This applies to Unreal, Unity, Godot all of them, if you have something which will load your models, compile/apply your shaders and render to the screen you have a graphics engine. If you have a threading model, memory or allocation handling, logging, input, user interface... All these module pieces form an engine.
The reason I am investing time working in my own such project is to explore those modules in which I find my experience or knowledge needing expanding, where I wish to trial alternative approaches, keep up with emergent new techniques or processes.
And of course for the content itself to explore the content creation tools; for instance I am very much a Blender beginner, and learning fast. I could not say this just three months ago.
The major advantage to me in performing this kind of exploratory work at home in my own time is of course that I take a confidence and an assuring confidence back to my real work, as a leader of a small team I feel I am equipped to jump into pair program and just help. I feel equipped going over a diverse or new code base; for instance recently I explored the Dagor engine used by WarThunder and the Little Vulkan Engine by Brendan Gaela.
Chronologically XVE has gone over many internal milestones, long before I began posting anything to YouTube or this blog about it, including:
CMake & Project Structure
Coding Standards
Git & Commit Hook integration for Jenkins Continuous Integration Builds
Test Framework
Module Design
Base
Renderer
Data loading
XML
CSV
Wavefront Obj
Generated type definitions (a whole generator suite written in python
Entity Component System
Threading Model
Thread pool
Anonymous Async Dispatch
Promise/Future Standard Exploration
Memory/Allocator Models
Slab Allocators
Dynamic Allocators
RPMalloc
Standard Allocator API (Custom)
Input Framework
XInput/DirectInput
SDL2 Input
SDL3 Input
GLFW Input
Custom personal exploration
And only after all this did I begin exploring actual game content and systems and component and entity relationships to represent the game design concepts.
The engine becomes a tool, a tool to achieve the delivery of the experience we want our players to experience and enjoy, so they return time & again to our game.
The game is key, and if done right the player should never know what engine or framework is being used to deliver that experience to them.
For about two years I've had a home game engine project, this has just been a little sandbox in which I have been able to experiment with graphics API's, systems, memory, threading models and other such "Game Engine" like things; it has simply been a learning aid to keep myself invigorated.
You see I work on a AAA game engine, for a game yet to be released and that engine does a lot of things its way, tens of engineers work on it in the "Engine" space.
I therefore wanted a space of my very own in which I could explore, the key piece I have done which ape that real engine have been using an Entity Component System.
My Ecs is quite different from the one at work, my focus is on game objects being made of many entities and those entities carrying discrete components to add their functionality. A very data driven ideal.
A great example might be simply putting a model on screen, lets take a complex object. The Missile Launcher as a case study and we will be looking at the code before images from the running application.
To place the game object entity I create the Object structure, filling it out and assign it a transform and launcher state instance, these components give the engine a key into the nature of what this entity is. There are many explanations of Ecs out there, but simply put we get an entity handle (an Id) and assign to it certain component types. The presence of these components then tell us everything we want to know about the entity:
components::Object launcherObject
{
.mId =GetNextGlobalObjectId(),
.mDebugName ="Launcher"
};
components::LauncherState state;
components::Transform3d launcherTransform
{
.mPosition = { 4, 1.5, 4 },
.mRotation = { 0, 0, 0},
.mScale = { 1, 1, 1 }
};
This could be all we need for the entity, indeed this is a design decision I am yet to fully explore. However, in the actual code I immediately want the base model for the renderable to have this same transform.
Adding this is as simple as assigning more components:
components::RenderablebaseRenderable
{
.mMesh=GetMeshIndexForName("Launcher_Base"),
.mTextures { GetTextureIndex("swatch.png") },
.mVisible=true,
.mBlended=false
};
components::Shadershader
{
.mShader=GetShaderIndex("Brambling1"),
.mWireframe=false,
.mLighting=true,
.mFog=false,
.mCameraRequried=false
};
The renderable and shader component are very strong indicators of quite how this works, an entity without these components will not ever draw.
In fact there are three components needed for the "Draw" system to pick up the entity and run the graphics API calls over the entity, these are the Transform, the Renderable and the Shader components; these three together indicate that this is something the engine will draw.
And the system simply iterates all the entities in this view and we have just those entities to show.
(At this point I know a bunch of you are lost, but lets just think of this like we've divided the thousands of entities in our game such that only those with these three entities will appear in our View).
We have right now though just got the object itself showing and the model showing is only the base, I want to rotate this base.... I have a component for that:
components::ManualRotationYmanualRotationControl;
Assigning this component to the entity and the functionality this component brings is assigned to our launcher!
This is the key power of an Entity Component System, we can author discrete and well defined features as a component and which operate on the member data within that component and then assign it to any other entity we desire. Manually Rotating the entity around the Y (or up axis) is a good example.
Another might be the speed of a vehicle.
We however want to add a body model to our launcher object, our second model looks like this:
Adding a child entity to this launcher object we can keep all the components separate for the body than the base:
components::Transform3dbodyTransform
{
.mPosition= { 0, 2, 0 },
.mRotation= { 0, 0, 0},
.mScale= { 1, 1, 1 }
};
components::RenderablebodyRenderable
{
.mMesh=GetMeshIndexForName("Launcher_Body"),
.mTextures { GetTextureIndex("swatch.png") },
.mVisible=true,
.mBlended=false
};
components::ShaderbodyShader
{
.mShader=GetShaderIndex("Brambling1"),
.mWireframe=false,
.mLighting=true,
.mFog=false,
.mCameraRequried=false
};
components::ManualRotationXtiltControl;
constautobody{ CreateEntityWithParent(launcher,
std::move(bodyTransform),
std::move(bodyRenderable),
std::move(tiltControl),
std::move(bodyShader)) };
Because we have added this second renderable as a child (the parent being the launcher itself) the transform is hierarchical and the launcher now looks like this:
We want the launcher to carry missiles, but where to place them? Well, I have invented a "socket" system, that when you place a socket entity onto something you can find the socket and insert something into it...
std::array<glm::vec3, 4>missilePositions
{
glm::vec3{ -1.2, 0.5, 0.5 },
glm::vec3{ -1.2, 1.0, 0.5 },
glm::vec3{ 1.2, 0.5, 0.5 },
glm::vec3{ 1.2, 1.0, 0.5 }
};
for (uint32_tindex{ 0 }; index<missilePositions.size(); ++index)
We can see that for each launcher in the Launcher View (which is just any object with a components::LauncherState) and we know we can pull out that component and work on adding a missile if the launcher timeout has passed the reload time; calling AddMissileToSocket you can imagine looks for children of the launcher which have the components::LauncherSocket component type, and voila we have the transform from the base, the body and the socket to place the missile.
Putting all this together and we get:
You can see the component have their own UI (ImGui) controls, that one has complete control over the whole entity and each individual component.
And the parent-child relationship between different entities within the object allow for really complex game objects to be described in fairly quick turn around times.
Another example of this is my test vehicle, which has a rolling wheel to match the movement; the movement belongs to the vehicle, which is a game object with a renderable. But the wheel itself is a child, it has a renderable too, but also its own transform and its own "Wheel" component, which has the discrete maths for the circumference and rotation.
The effect of rotating the wheel per frame is even its own other component, so that we can assign the same "Rotate per frame" component to anything in our scene.
With all this technology in place, the basic rendering engine as you can see (in OpenGL 4.3) I am now placed to expand the amount of content and start to build an actual game.
You see a game engine, or any engine, can only really fulfill its potential and for me complete the learning round trip by creating and driving something, for me this will be a game.
The missile launcher is perhaps a hint as to the kind of game I am picturing. but the models I am working on as of new years night are perhaps stronger clues:
The Entity Component System has been a key implementation for my to progress onto content creation and, besides a few performance fears when I scale up the combat scenes I hope to deliver, I believe it to be the best choice for fast and easy iteration on a theme.
The mental leap of a game object being one or many entities, each with their own features dividing up the mammoth task of implementing all the features of a game for myself as a solo developer has been absolutely key.